
CAN MOBILE PHONE DATA PREDICT WOMEN’S ECONOMIC EMPOWERMENT IN AFRICA?
How can we learn about women’s empowerment when large-scale survey data are not available? Big data generated from mobile cell phones hold significant potential to fill in gender data gaps. Call detail records (CDRs) -- which are produced whenever a mobile phone is used -- contain a wealth of information on users’ behavior. The number of different people a user calls may reveal something about users’ social networks, how frequently users purchase mobile minutes and/or data may correlate with socio-economic status, and the location of cell towers, through which phone calls are routed, provide insights into users’ mobility.
With the global rise in mobile phone usage, we are seeing more applications of CDRs in development research. They have been used to study poverty, human migration, the spread of epidemics, and disaster response. CDRs also show promise for understanding gender issues. Researchers have applied machine-learning techniques to CDRs to predict the sex of phone users and phone users’ socioeconomic status.
Inspired by these applications, we recently examined the feasibility of using CDRs to predict women’s and men’s economic empowerment. In the study, economic empowerment was proxied by indicators of employment status, ownership of assets (land and house), and decision-making about the use of household income (Table 1). The research reveals the substantial promise of this approach. Still, important limitations must be recognized. First, it is critical that CDRs are used ethically and respectfully of data privacy and security. Second, non-representativeness related to conducting analyses on a subsample of the population (mobile phone users) is an issue that deserves concerted attention.
Collecting ground-truth data
How did we go about predicting economic empowerment from CDRs?
We started by collecting ground-truth data through a phone survey with a random sample of subscribers of MTN Uganda, one of the largest mobile service providers in the country. A sample of 10,417 (3,946 women and 6,471 men) respondents was successfully interviewed. The phone survey included seven questions. Three of these focused on the economic empowerment indicators mentioned earlier – employment status, ownership of assets (land and house), and decision-making about use of household income (see Table 1 below for the exact questions).
Table 1: Economic empowerment questions
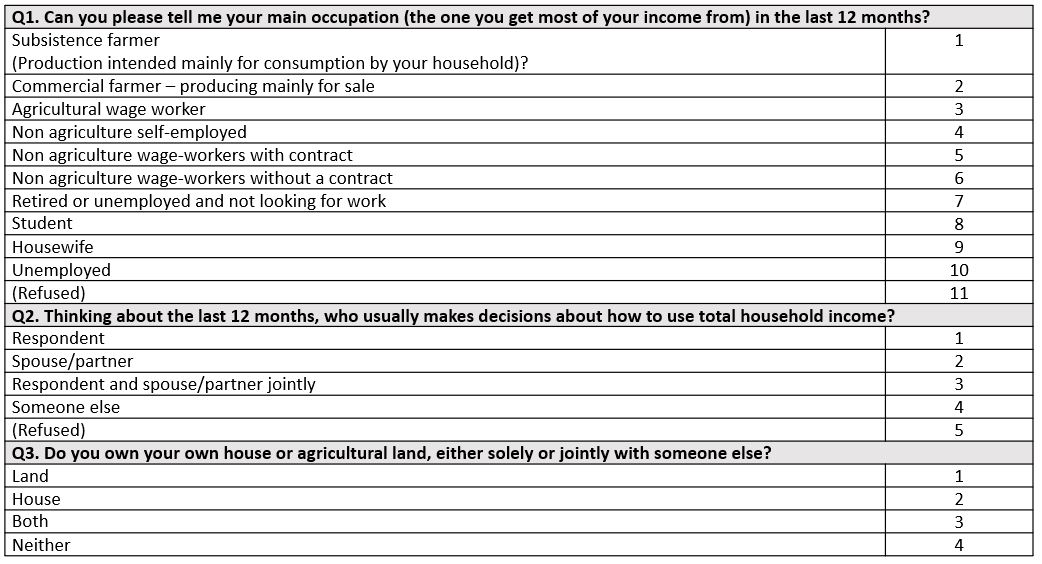
The other questions asked about respondents’ sex, age, marital status, SIM card usage, and whether the phone was shared with other family members.
Developing machine-learning models
We developed machine-learning (ML) models using data from CDRs for over 12 million MTN Uganda subscribers, including the ground-truth survey respondents. The CDRs covered the 2-month period of September-October 2019, which overlapped partially with the ground-truthing phone survey. From the CDRs, we extracted 167 distinct variables or ‘features’ related to phone usage, contacts, location, and recharging patterns. We linked the CDR features with the ground-truth data using respondents’ phone numbers. This new dataset was used to develop supervised ML algorithms to predict five user characteristics (referred to as “classification problems”): sex, land ownership, house ownership, occupation (whether the user worked in agriculture, in non-agriculture, or was not in the labor force), and participation in decisions over income.
So how do supervised ML algorithms work? The new data set – the matched ground truth data and user CDRs – is divided into a training and a testing set. Using the training data set, the ML algorithms are fed the CDR features and the associated user characteristics collected with the ground truth survey. This is repeated until eventually the algorithm picks up a pattern between the CDR features and the respective user characteristics. Now, the ML algorithm can be fed brand new CDR features (specifically, those from the testing set), and it will now be able to predict the user characteristics. In this way, the testing set is used to evaluate how well the algorithms perform before they are applied to the full MTN database.
To evaluate the performance of the different algorithms, we used a simple baseline prediction based on the majority class reflected in the data. This is standard procedure in data science, but a little different from the way we typically do things in applied economics. What it amounts to is this: if 38% of mobile phone users in the sample are female (as is the case in our data), then a model that predicted that all phone users are male (the majority class) would be correct for 62% of users (equal to the proportion of male users in the sample). We call this the model’s baseline predictive accuracy. The better the model, the more it should exceed this baseline predictive accuracy. Table 2, column 1, shows the baseline predictive accuracy for each separate classification problem.
Model evaluation and interpretation of the results
How well did our ML algorithms perform? We started by predicting each of the five user characteristics separately (Table 2, column 2). Next, to see if the predictive accuracy would improve, we explored predicting the economic empowerment indicators, conditional on predicting user sex (Table 2, columns 3-4) as well as predicting the user sex, conditional on predicting economic empowerment (Table 3).
While the models for sex, land and home ownership, and occupation all significantly exceeded baseline accuracy (Table 2, column 2), the model for decision-making over income failed to do this. This was likely due to the lack of variation in the data—84% of users reported participating in decisions on income—but it also revealed just how difficult it was to predict empowerment. While employment and land/house ownership are undoubtedly related to economic empowerment, decision-making was, by far, the most direct indicator of empowerment we tested.
Table 2. Accuracy of the best classifier of each problem in the testing set
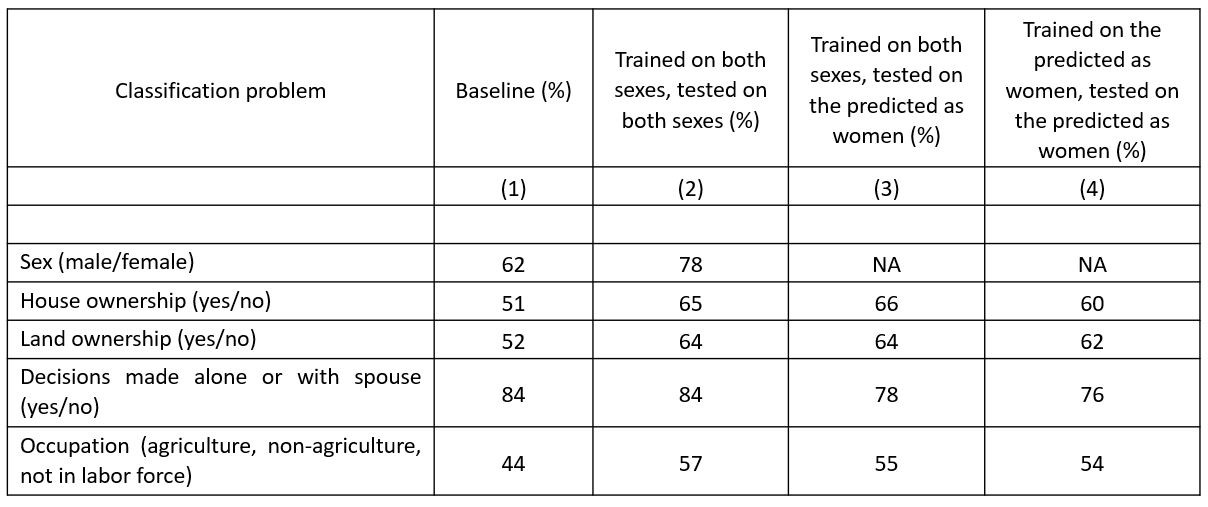
Column 3 and 4 of Table 2 show the estimates from the conditional predictions of economic empowerment on users’ sex. There are no noticeable improvements in the predictive accuracies over the separate predictions for the five indicators (Table 2, column 2). However, for the conditional prediction of user’s sex on predicted economic empowerment, we achieved high accuracy rates ranging from 81% to 87% depending on the respective indicators (Table 3). This suggested that the ML algorithms had a harder time picking up patterns in the CDRs to predict empowerment indicators than picking up patterns in the CDRs to predict the sex of users; there was more heterogeneity in the indicators of economic empowerment than in indicator users’ sex. That is, once ML algorithms predict indicators of empowerment (e.g., whether the individual owned a house or land), predicting users’ sex can be done with significantly higher accuracy compared to predicting sex without conditioning on empowerment. None of the approaches did well predicting women’s or men’s decision-making over income.
Table 3. Accuracy of the best classifier on sex prediction, conditional on the empowerment indicator prediction
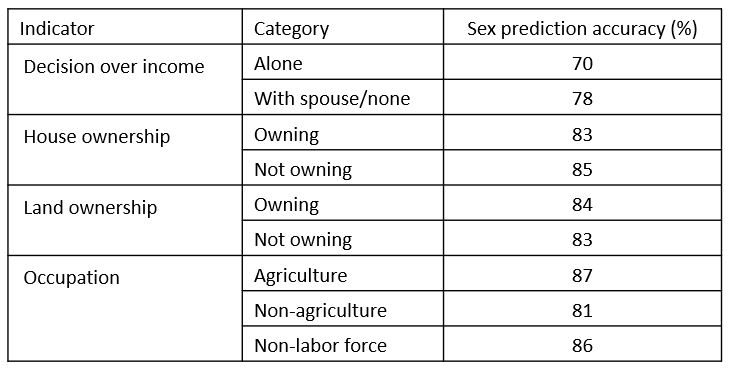
Although predicting decision-making over income was a challenge, the rest of the results were encouraging and provided a proof of concept that CDRs could be operationalized for tracking progress on gender equality and women’s economic empowerment in a developing country.
However, more research and modelling are needed. For example, it would be great to be able to identify the features generated from CDRs (e.g., the duration of incoming calls, average number of unique contacts per day, amount and frequency of credit recharging, etc.) that are most informative for gender analyses, and the types of gender indicators that they are best suited for predicting. There is also a need to examine the applicability of the models to other countries, including fragile and conflict contexts, where traditional data collection is often impossible.
Acknowledgments. This was a joint project of the CGIAR Platform for Big Data in Agriculture and the CGIAR Program on Policies, Institutions, and Markets (PIM) and for this study, the research team partnered with Dalberg Data Insights (DDI). Dalberg Data Insights were an invaluable partner for the study. Through their on-going data sharing agreement with MTN Uganda, they had access to users’ CDRs. They also provided technical leadership and developed the machine-learning models.
Vanya Slavchevska is gender and social inclusion scientist in the Crops for Nutrition and Health Lever at the Alliance of Bioversity International and CIAT. Greg Seymour is a research fellow with the Environment and Production Technology Division of the International Food Policy Research Institute (IFPRI). Brian King is coordinator of the CGIAR Platform for Big Data in Agriculture.
This story is part of the EnGendering Data blog which serves as a forum for researchers, policymakers, and development practitioners to pose questions, engage in discussions, and share resources about promising practices in collecting and analyzing sex-disaggregated data on agriculture and food security.
If you are interested in writing for EnGendering Data, please contact the blog editor, Dr. Katrina Kosec.
Photo credit: Nandini Harihareswara/USAID

